最进在看 python爬虫 正好最近金融闹得沸沸扬扬
import pymysql
from urllib.request import urlopen
from bs4 import BeautifulSoup
def savep2p(name,inde,company,addrs,date,reason,url):
try:
conn = pymysql.connect(host='127.0.0.1',user='root',passwd='********',db='mysql',charset='utf8')
conn = conn.cursor()
conn.execute('use spider')
savesql = 'insert into `problemp2p` (`name`,`inde`,`company`,`addrs`,`date`,`reason`,`url`) values (%s,%s,%s,%s,%s,%s,%s)'
conn.execute(savesql,(name,inde,company,addrs,date,reason,url))
conn.connection.commit()
except:
conn.close()
def get_url(url):
response = urlopen(url)
req = BeautifulSoup(response.read(),"lxml")
p2plist = []
result = req.findAll('tr',{'class':'gra'})
for i in result:
#print(i)
company = i.find('td',{'class':'company'}).get_text()
name = i.a.get_text()
addrs = i.find('td',{'class':'region'}).get_text()
date = i.find('td',{'class':'problem_time'}).get_text()
reason = i.find('td',{'class':'blacklist'}).get_text()
url = i.find('td',{'class':'The_url'}).get_text()
p2plist.append([name,company,addrs,date,reason,url])
return p2plist
p2plist = get_url(url='http://wj.china.com.cn/Problem/lists.html')
#print(len(p2plist))
for i in p2plist:
name = i[0]
inde = '问题平台'
company = i[1]
addrs = i[2]
date = i[3]
reason = i[4]
url = i[5]
savep2p(name,inde,company,addrs,date,reason,url)
print('>>>>>>>>完成')
存到spider下面的problemp2p表里面啦
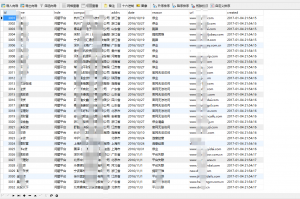
爬完之后一看吓一跳3000多个
数据不一定精确 ==